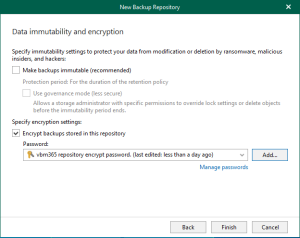
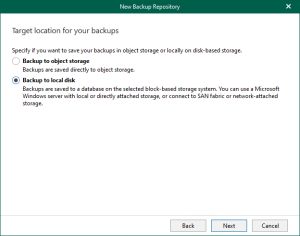
Visual Modality <LIMITED × 2027>
: Align the visual features with textual data (e.g., image captions or user prompts) using techniques like Cross-Modal Alignment to ensure the system "understands" the relationship between words and pictures.
When drafting visual features, consider these components of the visual mode: Multi-Modal Communication: Writing in Five Modes visual modality
To draft a feature using the , you are incorporating information that an audience can see —such as images, videos, symbols, or layouts—to communicate meaning more effectively than text alone. In technical fields like AI and computer vision, this involves extracting spatial features (like edges, textures, or shapes) from images using models like Convolutional Neural Networks (CNNs). Feature Concept: "Context-Aware Visual Search" : Align the visual features with textual data (e
: Implement an " Action-Modality Match " approach where users can switch between typing a brief and uploading a screenshot to iterate on designs or search results visually. Key Visual Elements to Include and scene geometry.
This feature allows a system to understand not just what is in an image, but how those visual elements relate to specific user goals or queries.
: Use deep learning architectures like VGG-16 or Transformer-based models to identify objects, bounding boxes, and scene geometry.